AI chips have become a crucial trump card in the US-China tech competition.
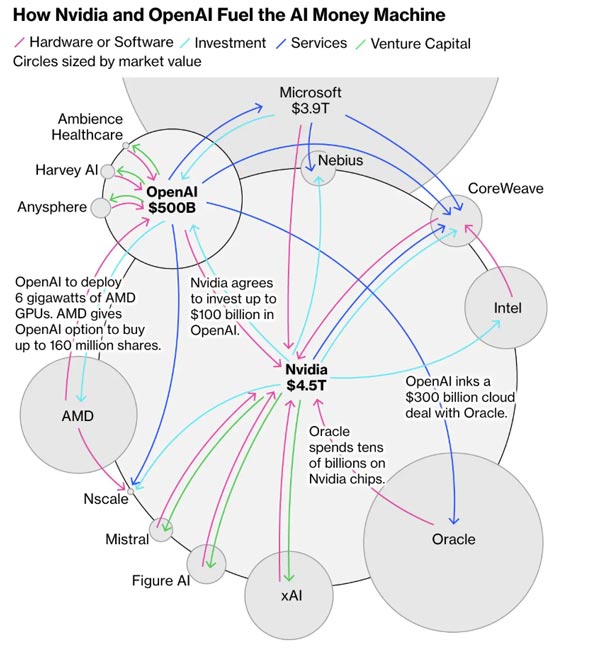
Over the past two weeks, Nvidia, with a market capitalization of $4.5 trillion, announced it would invest up to $100 billion in OpenAI over the next decade, with the latter purchasing and deploying 4-5 million Nvidia GPU chips. Simultaneously, on October 7th, AMD announced a four-year, multi-billion dollar computing chip supply agreement with OpenAI, under which OpenAI will acquire up to 10% of AMD's shares. Oracle also reached a trillion-dollar partnership agreement with OpenAI.
After the announcement of the AMD-OpenAI partnership, AMD's stock price skyrocketed, reaching its largest gain in nearly a decade. This marked the first time the perennial runner-up in the data center AI chip market faced off against Nvidia, and resulted in a trillion-dollar "circular trade" for OpenAI.
In China, DeepSeek released the DeepSeek-V3.2-Exp model in early October. Subsequently, Chinese chip companies such as Cambricon and Huawei Ascend announced compatibility. Huawei even announced plans for mass production of its Ascend 910 series chips, slated to launch the Ascend 950PR in the first quarter of 2026, featuring Huawei's proprietary HBM, and the Ascend 970 in the fourth quarter of 2028.
In addition, Cambricon's stock price has continued to rise, surging 124% between July and September. Its current market capitalization reached 521 billion yuan, surpassing Tokyo Electron, Japan's largest chip manufacturing equipment manufacturer, and becoming one of the most valuable semiconductor design companies in China's A-share market.
Nvidia CEO Jensen Huang recently stated that China lags only "a few nanoseconds" behind the United States in the chip industry and possesses immense potential in chip R&D and manufacturing. He called on the US government to allow American technology companies to compete in markets like China to "increase US influence."
Clearly, the US's tightening of AI chip export controls on China has actually accelerated the development of Chinese AI chips, leading to a cooling of the H20 chip market in China. Today, despite Nvidia's products accounting for over one-third of China's AI chip sales in 2024, Jensen Huang's team remains caught in the middle of the Sino-US AI chip competition.
On one hand, the US continues to expand its AI chip export controls on China. For example, the latest "GAIN AI" Act requires Nvidia to prioritize supplying AI chips to US companies before exporting advanced AI chips to China. This could cause Nvidia to miss out on a slice of China's $50 billion AI computing market.
On the other hand, market competition is intensifying: foreign companies such as AMD, Google, Microsoft, and Broadcom, as well as Chinese companies like Huawei, Cambricon, and Moore Threads, have all developed more cost-effective AI computing chip products, and Chinese AI computing chips have gradually secured deployment orders. Furthermore, internet giants like Alibaba, Tencent, Baidu, and ByteDance are also increasing their investment in chip R&D and design, striving to gain greater autonomy and control over their supply chains. According to Epoch AI data, OpenAI spent $7 billion on computing power over the past year, with $5 billion going to large-scale AI model training.
Morgan Stanley predicts that the total cost of global AI infrastructure construction could reach as high as $3 trillion (approximately 21 trillion RMB) over the next three years. According to a Deloitte report, with the booming development of new technologies such as AI and 5G, global semiconductor industry sales revenue will reach a record $697 billion in 2025, and sales are expected to exceed $1 trillion by 2030.
Morningstar analyst Brian Colello said, "If we experience an AI bubble and its eventual burst a year from now, this deal (Nvidia's investment in OpenAI) may be one of the early clues."
In response to inquiries about recent developments by Chinese chip companies, an Nvidia spokesperson stated that competition has undoubtedly arrived.
Wang Bo, CEO of Tsinghua-affiliated AI chip company Qingwei Intelligence, told me that new architecture AI chips, such as reconfigurable ones, can provide China's AI computing power with a path forward beyond Nvidia's GPUs. To capture a larger share of the AI chip market, China needs to offer products with a price-performance advantage five times greater than competitors. "The industry currently has a dominant competitor, such as Nvidia or Intel, with a commanding market share. You absolutely cannot follow their path or you'll be completely crushed."
The DeepSeek craze has helped propel China's AI chip industry to a new level.
Since October 2022, the United States has launched multiple rounds of export controls targeting China's semiconductor industry, attempting to prevent China from manufacturing advanced AI chips or using American chips to train advanced models.
In December 2024, the Biden administration expanded its export restrictions on China for the final time. These restrictions included restrictions on HBM (high-bandwidth memory) required for advanced AI chips and a red line on computing power density, aimed at limiting China's ability to develop large-scale AI models. Consequently, Chinese internet cloud companies, which previously relied heavily on Nvidia chips, have begun considering deploying Chinese AI chips.
At the same time, the DeepSeek craze in 2025 has accelerated the adoption of Chinese AI chips and applications.
When DeepSeek released version 3.1 in August of this year, a statement from its official website garnered market attention: "UE8M0 FP8 is designed for the upcoming next-generation Chinese chip." This statement heightened market interest in the latest developments in Chinese AI chips and also caused a drop in Nvidia's stock price.
Currently, DeepSeek training costs are far lower than leading American AI models. On September 18th, Liang Wenfeng served as the corresponding author of the cover article in the prestigious journal Nature, which revealed that the DeepSeek-R1 model training cost only $294,000. Even with the approximately $6 million base model cost, it still far lower than the AI training costs of OpenAI and Google.
Jensen Huang told me in July of this year that DeepSeek-R1 is both a revolutionary model and the first open-source inference model, and it is highly innovative. Chinese AI models are highly efficient and open, allowing them to be adapted to any application scenario. It's even possible to create a company, product, or business based on these open models.
"Four years ago, Nvidia's market share in China was as high as 95%, but now it's only 50%. If we don't compete in China, but instead allow China to develop new platforms and build a rich ecosystem, and if these are not American, their technology and leadership will spread globally as they promote AI technology," said Jensen Huang.
By the end of 2024, Nvidia will account for over 90% of all global AI acceleration chip sales. According to its latest quarterly financial report for August 2025, Nvidia's data center revenue reached $41.1 billion, a year-on-year increase of 56%, making it Nvidia's largest revenue segment.
Jensen Huang stated in August that production of Nvidia's Blackwell Ultra architecture chips is progressing at full speed, with strong demand, coinciding with the rapid growth of model performance driven by inference-based AI models. The AI race has begun, and Blackwell is at the heart of it.
He believes that the $600 billion in annual capital expenditures associated with data center infrastructure construction only accounts for the four largest spenders. Numerous other companies will also invest in AI. Over the next five years, Nvidia will seize a $3 trillion to $4 trillion AI infrastructure opportunity through chips based on architectures like Blackwell and Rubin. Over time, AI will accelerate GDP growth.
However, DeepSeek is not the only Chinese AI company not reliant on US technology. As US restrictions on China continue to tighten, Chinese cloud vendors like Alibaba, Tencent, and ByteDance's Volcano Engine have begun stockpiling Nvidia GPUs while exploring Chinese alternatives.
Financial reports show that due to US restrictions on H20 sales to China, Nvidia incurred $4.5 billion in H20 inventory expenses in the first quarter of fiscal year 2026, and sales decreased by $4 billion in the second quarter.
At the same time, the Chinese AI chip market is experiencing a supply shortage. It's reported that several Chinese AI chip companies, including Alibaba, Cambricon, Qingwei Intelligence, Moore Threads, and BiRen Technology, aim to challenge Nvidia and become one of China's core AI computing chip manufacturers.
Recently, CCTV reported on the "Construction Progress of China Unicom's Sanjiangyuan Green Power Intelligent Computing Center Project," revealing that Alibaba's Pingtou Ge subsidiary has recently developed a PPU chip for AI data centers. Its key performance indicators surpass Nvidia's A800 and are comparable to the H20, while consuming less energy.
According to the author, Cambricon's largest internet customer is currently ByteDance, with pre-orders exceeding 200,000 chips. Alibaba and Baidu have already entered mass production of their own self-developed chips. Tencent is currently gradually releasing its previously stockpiled chips and is also purchasing Suiyuan products.
In September of this year, Huawei launched its most powerful AI chip ever. Huawei announced plans to launch the Ascend 950PR, featuring its own HBM chip, in the first quarter of 2026; the Ascend 950DT in the fourth quarter of 2026; the Ascend 960 in the fourth quarter of 2027; and the Ascend 970 in the fourth quarter of 2028, challenging Nvidia's dominance in the AI market.
According to Caixin, semiconductor industry experts estimate that Huawei's Ascend AI chip shipments will be approximately 300,000 to 400,000 units in 2024, while Cambricon shipments will exceed 10,000. In 2025, Huawei's Ascend shipments may fall slightly below 1 million units, while Cambricon shipments will increase to around 80,000 units. Cambricon shipments are expected to double in 2026.
However, Huawei Vice Chairman and Rotating Chairman Eric Xu stated that due to US sanctions, Huawei cannot produce chips at TSMC, resulting in a gap in computing power per chip compared to Nvidia. However, Huawei has invested heavily in supernode interconnect technology and achieved breakthroughs, enabling it to achieve supernodes with tens of thousands of cards, thus achieving the world's highest computing power.
Huawei founder Ren Zhengfei stated in June that although Huawei's Ascend chip is "a generation behind" its US counterparts, it can achieve state-of-the-art performance through stacking and clustering technologies.
Regardless of the challenges, we clearly cannot underestimate China's ability to catch up in AI chips.
Moore Threads founder and CEO Zhang Jianzhong recently stated that the current difficulties facing GPU chip manufacturing stem from three main factors: the international embargo on high-end chips, sales restrictions on high-end HBM memory, and limitations on advanced process technology. The market currently demands over 7 million GPU computing cards to support generative AI and AI agent technologies. Over the next five years, demand for AI computing power will continue to grow 100-fold. Assuming that each wafer produces approximately 20-30 units of effective computing power, China still faces a production capacity gap of 3 million GPU cards. In the short to medium term, the Chinese computing market faces a shortage of intelligent computing power, and production capacity is unlikely to meet demand.
On September 26th of this year, Moore Threads successfully passed the IPO review just 88 days after submitting its prospectus, becoming the fastest AI chip company to be reviewed on the Science and Technology Innovation Board (STAR Market) and poised to become "China's first GPU stock." Moore Threads plans to raise 8 billion RMB in this IPO, the largest fundraising by an A-share listed company this year and the largest IPO in the semiconductor design sector. The company stated that the funds raised will be primarily invested in the research and development of next-generation AI training and inference chips, graphics chips, and AI SoC chips, solidifying its leading position in high-performance computing.
According to its financial report, Moore Threads' operating revenue in the first half of 2025 reached 702 million RMB, exceeding the combined revenue of the previous three years, with a compound growth rate exceeding 208% over the past three years. The company's gross profit margin increased significantly from -70.08% in 2022 to 70.71% in 2024. As of June 30, 2025, the company is in negotiations with clients expected to receive orders totaling over 2 billion yuan. Management anticipates achieving consolidated profitability as early as 2027.
Currently, a simple task call in a mainstream AI agent consumes approximately 100,000 tokens, while a complex task call can exceed 1 million tokens. By the end of June 2025, China's average daily token consumption had exceeded 30 trillion yuan, a 300-fold increase in just a year and a half.
Zhang Jianzhong emphasized that AI is entering the era of intelligent agents, and computing power demand will experience explosive growth.
Jensen Huang has stated that AI is a vibrant, entrepreneurial, high-tech, and modern industry. American companies should trade freely with China, otherwise they risk ceding their advantage in the AI race to China.
The latest data from research firm IDC indicates that China's AI acceleration server market will reach $16 billion in the first half of 2025, more than doubling from the first half of 2024. China already has over 1.9 million acceleration chips. The market is projected to exceed $140 billion by 2029.
IDC predicts that from an acceleration technology perspective, demand for non-GPU cards such as NPUs and CPUs will continue to grow in the first half of 2025, far outpacing GPUs and accounting for 30% of the market share. From a brand perspective, Chinese AI chips are becoming increasingly popular, accounting for approximately 35% of the total market share.
Computing bottlenecks have arrived, and server chips urgently need new architectures, new storage, and new communications.
For a server in a data center, computing (chip computing power), communications (supernodes, NVLink), and storage (HBM, DDR, etc.) are the three most core elements.
As the industry enters the post-Moore's era, iterating on an AI chip requires improving PPA—boosting performance, reducing power consumption, and shrinking area.
In essence, improving PPA requires a coordinated effort across multiple dimensions, including architecture design, process selection, and software optimization. The core approach is to accelerate the processing speed of AI tasks (such as matrix operations and feature extraction), optimize computing efficiency and data flow efficiency through hardware innovation and software-hardware collaboration. This balance and breakthrough in PPA are achieved while meeting AI computing requirements.
However, currently, from a process perspective, "Moore's Law" is slowing down. The upgrade from mature processes (such as 14nm) to advanced processes (such as 7nm, 4nm, and 3nm) has not resulted in the expected improvement in AI computing power, and chip costs have also risen sharply.
Handel Jones, CEO of International Business Strategies (IBS), once stated that the average cost of designing a 28nm chip is $40 million; while a 7nm chip costs as much as $217 million, a 5nm chip costs $416 million, and a 3nm chip will cost a whopping $590 million. Multiple public data sources indicate that the overall design and development costs for a 3nm chip could approach $1 billion (approximately RMB 7.2 billion). The high price tag is primarily due to factors such as foundry costs, R&D investment, equipment procurement (especially EUV lithography equipment), and yield rates.
Meanwhile, Qualcomm's newly released fourth-generation Snapdragon 8s, based on a 4nm process, boasts only a 31% improvement in general computing (CPU) performance compared to previous Qualcomm Snapdragon products. The Intel Core Ultra7 165H, featuring the latest process and chiplet technology, only achieves an approximately 8% performance-per-watt improvement over the previous 10nm Core i7-1370P. TSMC's latest N2 process boasts only a 10%-15% performance improvement over its predecessor.
Clearly, future developments in advanced process technology will not significantly improve AI chip performance or cost-effectiveness. At this year's GTC conference, Jensen Huang began touting the surge in demand for large-scale tokens to highlight the importance of the B200 to the AI chip market, rather than chip performance.
A semiconductor industry insider privately told me that China is wise not to pursue advanced process technology. After 12nm, the performance gains from process technology are less pronounced. Therefore, China's manufacturing process is likely to remain severely limited for a considerable period of time. How to continuously develop chip computing power within this limited capacity is a crucial issue.
Thus, the computing bottleneck has arrived, and server AI chips urgently need new architectures, new storage solutions, and new communication networks to enhance their capabilities.
Wei Shaojun, a professor at Tsinghua University and chairman of the Integrated Circuit Design Branch of the China Semiconductor Industry Association, has bluntly stated that with external restrictions on China's advanced process chip research and development, China's access to manufacturing technologies is no longer as rich as before. Today, China's chip industry needs to focus more on technological innovation, focusing on design technologies that don't rely on advanced processes. This includes architectural innovation and microsystem integration. Chip companies must abandon "path dependence" and build their own product and technology ecosystems. Otherwise, they will never escape the passive position of following others.
"If we simply stick with existing chip architectures, we will likely only lag behind others and find it difficult to surpass them." Wei Shaojun believes that Asian countries, including China, should abandon the use of Nvidia's GPU architecture for AI chip development to reduce their reliance on Nvidia's technology. He believes that Asian countries are still emulating the United States in developing algorithms and large models, but this approach limits their autonomy and may bring the risk of becoming dependent on American technology. Asia's strategy must differ from the American model, especially in fundamental areas such as algorithm design and computing infrastructure.
Yin Shouyi, Dean of the School of Integrated Circuits at Tsinghua University, stated at the AICC2025 Artificial Intelligence Computing Conference that the amount of computing power each transistor can provide is essentially a question of computing architecture. Adopting new computing architectures offers the opportunity to improve transistor utilization, overcome the memory barrier that has constrained Chinese chip performance, and reduce chip power consumption, bringing new possibilities to chips. Breakthroughs in computing architecture will help boost the computing power of AI chips. Furthermore, using reconfigurable computing architectures for AI computing, and dynamically constructing the most suitable computing architecture through software and hardware programming, offers the opportunity to approach the performance of application-specific integrated circuits through automated hardware programming.
"Innovative architectures can break through traditional design thinking and address our fundamental computing power challenges, but we also need effective ecosystem support. Zhiyuan Research Institute's FlagOS is the ecosystem backbone for China's architectural innovation. Our collaborative efforts in both software and hardware will complement each other and help overcome China's computing bottleneck," said Yin Shouyi.
In addition to new architectures, improvements in storage and communications are also crucial.
Specifically, demand for AI memory chips such as HBM and DDR is expanding exponentially, with a single GPU node potentially consuming hundreds or even terabytes of storage. According to Micron data, AI servers require eight times the DRAM capacity of regular servers and three times the NAND flash memory capacity. A single AI server can require up to 2TB of storage, far exceeding the standard configuration of traditional servers.
As a result, this surge in demand has directly increased the cost share of memory chips in AI infrastructure. Recently, OpenAI's "Stargate" project partnered with Samsung and SK Hynix to procure 900,000 DRAM wafers per month, representing nearly 40% of global DRAM production.
Currently, the price of a single HBM chip exceeds $5,000, 20 times that of traditional DDR5 memory, yet boasts a high gross profit margin of 50%-60%, far exceeding the approximately 30% of traditional DRAM.
Tai Wei, general manager of the flash memory market, stated in March this year that the AI wave is shifting computing platforms from CPUs to GPU/NPU-centric ones, and demand for storage chips will also increase. Therefore, HBM high-bandwidth storage is widely used in the AI era. Currently, HBM accounts for nearly 30% of the DRAM storage industry, and by 2026, HBM4 will drive more customized demand in the industry.
In terms of communication networks, NVIDIA's network layout encompasses three primary technologies: NVLink, InfiniBand, and Ethernet. NVLink connects GPUs within a server or multiple servers within a cabinet-like server rack. Huawei's Ascend CLoudMatrix 384 supernode, connected by a high-speed interconnect bus, consists of 12 compute cabinets and 4 bus cabinets. Its total computing power reaches 300 petaflops, 1.7 times that of NVIDIA's NVL72. Its total network bandwidth reaches 269TB/s, a 107% increase over NVIDIA's NVL72, and its total memory bandwidth reaches 1229TB/s, a 113% increase. It will be further expanded to include the Atlas 900 SuperCluster, encompassing tens of thousands of GPUs, to support even larger-scale model evolution.
In addition, many AI chip companies are exploring new communication network technologies such as co-packaged optics (CPO), chiplets, optical communication networks, and DPUs, aiming to improve overall AI computing performance through intercommunication.
Lin Yonghua, Vice President and Chief Engineer of the Beijing Zhiyuan Artificial Intelligence Research Institute, stated that in the future, we need to promote better cost-effectiveness, lower energy consumption, and new computing architectures, continuously investing in innovation to enable more innovative hardware to be widely adopted and achieve greater commercial value. It is reported that the Zhiyuan Research Institute recently launched the "Zhongzhi FlagOS v1.5" system in collaboration with global ecosystem partners. Qingwei Intelligence, along with Cambricon, Moore Threads, Kunlun Core, Huawei Ascend, and Zhongke Haiguang, have become the only six "FlagOS Excellent Adaptors" in China.
However, China's AI chip ecosystem is currently incomplete, with severe production capacity shortages, and China still hoards a large number of overseas chips. According to data released by the General Administration of Customs in January this year, China's total integrated circuit imports will reach 549.2 billion units in 2024, a year-on-year increase of 14.6%. The total value of integrated circuit (chip) imports for the year will be US$385 billion, a year-on-year increase of 10.4%, accounting for 62% of global chip production. By comparison, China's crude oil imports in 2024 will be US$325 billion.
IDC China AI Infrastructure Analyst Du Yunlong believes that China's AI acceleration server market is undergoing a phase of scale expansion and domestic substitution. Breakthroughs are still needed in high-end computing power efficiency and ecosystem maturity. Future competition will shift from single-chip performance to system energy efficiency, open ecosystem collaboration, and green computing cost control. The industry must avoid low-level duplication and enhance international competitiveness through technological collaboration and standard optimization.



