A surge in the "scaling law" craze is sweeping the large model industry, with technology companies and research institutions investing vast resources in an attempt to achieve "better" model performance with "larger" data scales.
However, can this brute-force data expansion deliver the expected improvements in model performance? Is the ever-increasing scale of models reaching a point of diminishing returns or even negative returns?

Recently, foreign scholars P.V. Coveney and S. Succi issued a warning in a research paper:
Scaling laws have serious limitations in their ability to improve the predictive uncertainty of large language models (LLMs), and attempts to rationally increase reliability to the standards required for scientific inquiry are difficult to achieve.

They call this potential evolutionary path of pursuing model performance improvements through brute-force data expansion "degenerative AI," which catastrophically accumulates errors and inaccuracies. They argue that the core mechanism underlying LLM's learning ability—generating non-Gaussian output distributions from Gaussian input distributions—may be the root cause of its error accumulation, information catastrophes, and degenerative AI behavior.
They urge that the fundamental path to avoiding this dilemma is to return to the fundamentals of the problem, leveraging physical laws, problem-oriented small-scale networks, and human insight and understanding, instead of blindly expanding and investing resources.
◆ LLM Performance Growth, but Struggling
Currently, LLM has demonstrated impressive capabilities in natural language processing, often even being touted as having "reached superhuman performance." This development appears to foreshadow an unprecedented approach to tackling certain scientific problems.
The success stories of AI—particularly machine learning (ML)—have become some of the most widely discussed topics of this decade, ranging from victories in chess and Go to revolutionary predictions of protein structure. AI practitioners even snatched the 2024 Nobel Prizes in Physics and Chemistry from researchers in other fields.
However, the research team believes that machine learning is essentially a mathematical "black box" program, unable to understand the underlying physics. While introducing constraints based on physical laws can improve model convergence in certain situations, this fundamental flaw poses challenges for the application of machine learning in scientific and social fields.
Currently, only a handful of AI technology companies have the capability to train large, state-of-the-art low-level model (LLMs), and their energy demands are near-bottomless, with plans to build new nuclear reactors next to their data centers. However, while these companies closely guard their AI capabilities behind firewalls and keep the technical details of their commercial products secret, there are already signs that performance improvements are very limited.
For example, GPT-4.5 is estimated to have between 5 and 10 trillion parameters and may be based on a mixture of experts (MoE) architecture. Its inference process uses approximately 600 billion active parameters, and its API cost is 15 to 30 times that of its predecessor, GPT-4o, directly reflecting the increased model size.
This cost difference is even more extreme when compared to smaller distillation models. GPT-4.5 relies more heavily on model size and pre-training, which indeed leads to qualitative improvements in subjective dimensions (such as writing ability and empathy), but yields little substantive progress in verifiable domains like mathematics and science.
Another example is Llama 4 Behemoth, a model with 2 trillion parameters, whose performance appears to be below par for its scale.
The research team pointed out that the extremely low scaling exponent is the root cause of LLM's poor performance and the limited improvement in performance when training on larger datasets.
◆ LLM Scaling: Barriers
Despite the continued hype surrounding large models, computer scientists working in AI believe that even the most advanced AI chatbots produce significant errors that fall far short of the accuracy standards required for most scientific applications. Consequently, there is ongoing debate about the future of scalability and how to overcome the "barriers" hindering LLM scaling.
The research team used the example of derivatives to illustrate this point. Formally, a change in the sign of the exponent indicates the emergence of a "wall": at this point, even with additional computing resources, accuracy not only fails to improve but may actually decline significantly. This may sound paradoxical, but it is a reasonable result because it reflects negative effects that are not apparent below the "wall" threshold but begin to take effect after it is exceeded.
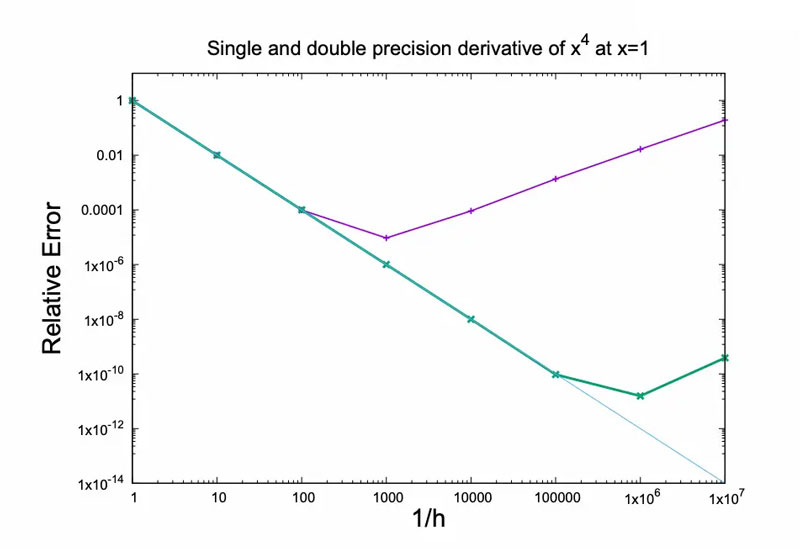
The research team stated that LLMs and their upgraded versions—large reasoning models (LRMs) and agentic AI—are far more complex than a simple derivative. Therefore, as models grow in size, they may face more potential "walls." Notably, digital systems are susceptible to roundoff errors, and these effects become increasingly pronounced as their complexity and the number of operations required to complete a task increase.
Thus, they believe that while the current scaling exponent of the LLM remains positive (it has not yet reached a "wall"), this small value is insufficient to support its continued development as hoped.
◆ Accuracy issues are more common.
It's widely believed in the industry that the accuracy of machine learning applications is highly dependent on the homogeneity of the training dataset; once a model is used on data from different datasets than the training and validation datasets, its performance can deteriorate significantly.
However, the research team noted that accuracy issues often occur even in homogeneous training scenarios. While the specific circumstances may vary, some common characteristics can be identified that hinder accuracy.
Lack of generalization in heterogeneous settings remains a key issue for machine learning, as generalization is essentially the true learning capability. "Validation" involves predicting unseen data from the same holdout dataset used for training, but this approach is of limited value because it resembles memorization rather than true learning.
In this regard, while many deep learning applications, particularly deep learning models (DLMs), are often praised for their exceptional ability to "predict unseen data" or, more broadly, exhibit reasonable human-like responses, this cannot be used to mask issues with the reliability of their predictions.
While AI tools from all sorts of tech companies continue to amaze us, this doesn't change the fact that they still make numerous errors, far exceeding the accuracy requirements of most scientific fields and many professional fields (such as law and education).
◆ Are LRMs and Agentic AI the antidote?
While LLMs' limitations in reliability and energy consumption are readily apparent, public discussions rarely delve into the technical details behind them. In fact, their development relies primarily on a highly empirical approach, often more like a process of trial and error.
Given the lack of universal reliability of LLM outputs, the tech industry is attempting to improve the trustworthiness of model outputs by using LRMs and Agentic AI, rather than simply increasing the amount of training data. While LRM offers improvements in some areas, its heavy reliance on empirical evidence makes effective quantification of performance more difficult. Agentic AI allows LLM to transcend simple chat functionality and generate real economic value. While this strategy undoubtedly makes sense from a business or product perspective, it lacks rigorous standards for scientific evaluation, even when integrating reasoning, multimodality, continuous learning, swarm intelligence, and other features that may emerge in the future.
This overall goal is undoubtedly meaningful: agents should be able to exhibit human-like "reasoning." The core idea is the "CoT" strategy, which systematically solves problems by emulating human sequential logical reasoning.
However, the question remains: Can these strategies establish a sustainable and scalable path? Current developments suggest this prospect remains uncertain.
The research team believes that a more constructive approach might be to enable LLM to perform the very function that generative models excel at: "hallucinate." Reasoning models and the use of multi-round tools are practical steps in this direction: LLM provides the next steps, while other components of the system handle evaluation and reward optimization. In this setting, hallucinations are not suppressed but rather guided, transforming the generated uncertainty into exploratory value.
AlphaEvolve employs a similar strategy, using LLM to imagine code variants and replacing reinforcement learning with evolutionary algorithms to guide selection and improvement.
◆ How to Avoid Degenerative AI?
The research team stated that their series of considerations collectively suggest a cautionary development path: "degenerative AI," which involves a catastrophic accumulation of errors and inaccuracies, particularly prone to occur in LLMs trained with synthetic data.
"While we have no intention of 'speaking down' any AI development, the theoretical analysis presented in this paper suggests that the scenario of degenerative AI is not only possible but, in some sense, inevitable."
They present the causal chain of degenerative AI as follows: The small spreading exponent (SSE) is "conclusive evidence" of non-Gaussian fluctuations (NGF); non-Gaussian fluctuations induce an unusual resilience to uncertainty (RoU), which results in the model's inability to accurately represent the "tail" of the data distribution, ultimately leading to information catastrophe (IC).
It's important to emphasize that while degenerative AI is an inherent possibility in current large-scale models, it's not inevitable.
Data is often mistakenly equated with information, which is clearly incorrect. In fact, there are various mechanisms that suggest that increasing data can sometimes lead to a decrease in the amount of information. For example, when data is conflicting or when misinformation is maliciously injected (e.g., fake news or data poisoning), this can lead to "information reduction."
The current expansion index is small, but still positive, indicating that the industry has not yet entered the "more data, less information" degradation zone. However, as repeatedly emphasized in this article, this low index indicates that the industry is in a phase of "extremely diminishing returns."
The research team believes that if we advance AI development solely through brute force and unsustainable computing power expansion without understanding and insight, degenerative AI is likely to become a reality.
In contrast, the industry has developed an alternative scientific approach: by constructing "world models," we can identify and extract true correlations from complex data, separating them from spurious ones.
“Simply relying on brute force expansion while ignoring the importance of scientific methods is undoubtedly a path doomed to failure.”



