DeepSeek has once again quietly shocked the world!
Their newly released and open-source OCR model fundamentally changes the rules of the AI game. The open-source Github project, DeepSeek-OCR, has garnered over 4,000 stars overnight. The accompanying paper ("DeepSeek-OCR: Contexts Optical Compression") explains this research achievement.

Many people are curious about what OCR is.
Traditional OCR is like a "text scanner," using optical technology to extract text from images and convert it into a format that both computers and humans can understand. For example, OCR plays a key role in digitizing large amounts of data, such as receipts, certificates, and forms.
DeepSeek, however, takes the opposite approach—it "maps" text information into visual images, then uses visual models to efficiently understand them. This innovative attempt aims to address a core pain point of large models—the computational challenges of processing long texts.
The result is stunning! A densely packed 10-page report is compressed into a single image, which the AI can understand at a glance. This information processing efficiency significantly reduces computational complexity, saving costs in a straightforward manner.
The paper, unsurprisingly, received rave reviews after its release, with some netizens dubbing it the "silicon-based theory of life evolution."
Karpathy, a founding member of OpenAI and former AI director at Tesla, who has recently been commenting on AI development, expressed his admiration for DeepSeek's new achievements, stating, "It's long past time to make vision the core of AI, rather than relying on crappy text segmenters."
An industry leader even lamented, "When text can be converted into visually understandable structures, the unification of language and vision may no longer be theoretical. This could be a key step towards AGI (artificial general intelligence).
DeepSeek's new research: Compressing large amounts of text into images, allowing models to understand directly from the images.
Essentially, DeepSeek-OCR deeply integrates visual and linguistic modalities, establishing a natural mapping through "visual-text compression," providing a new technical path for large multimodal models.
Previous large models can be described as "dancers in shackles." While they possess powerful language understanding capabilities, they are severely constrained by inefficient information input methods.
Take the case of models reading long texts. Each page of a financial report or paper contains thousands of tokens. Traditional methods can only recognize each word and sentence, resulting in an explosion of computational complexity. This inefficiency makes the application of large models in fields like law and finance difficult.
DeepSeek employed a clever idea: since a single image can contain thousands of words, why not compress this vast amount of textual information into a single image, allowing the model to understand it directly from the image?
To achieve this, DeepSeek equipped its OCR model with a three-part system: an image encoder, a mapping layer, and a text decoder. The image encoder, DeepEncoder (responsible for converting images into highly compressed visual tokens), has 380MB of parameters, while the text decoder (responsible for reconstructing text from compressed visual tokens) is a DeepSeekv2-3b model with 3MB of parameters.
The overall training data consists of four components: OCR 1.0 data (for traditional OCR tasks such as image and document OCR), OCR 2.0 data (for complex image parsing tasks such as geometry and diagrams), general visual data (to instill general image understanding capabilities), and plain text data (to ensure the model's language capabilities).
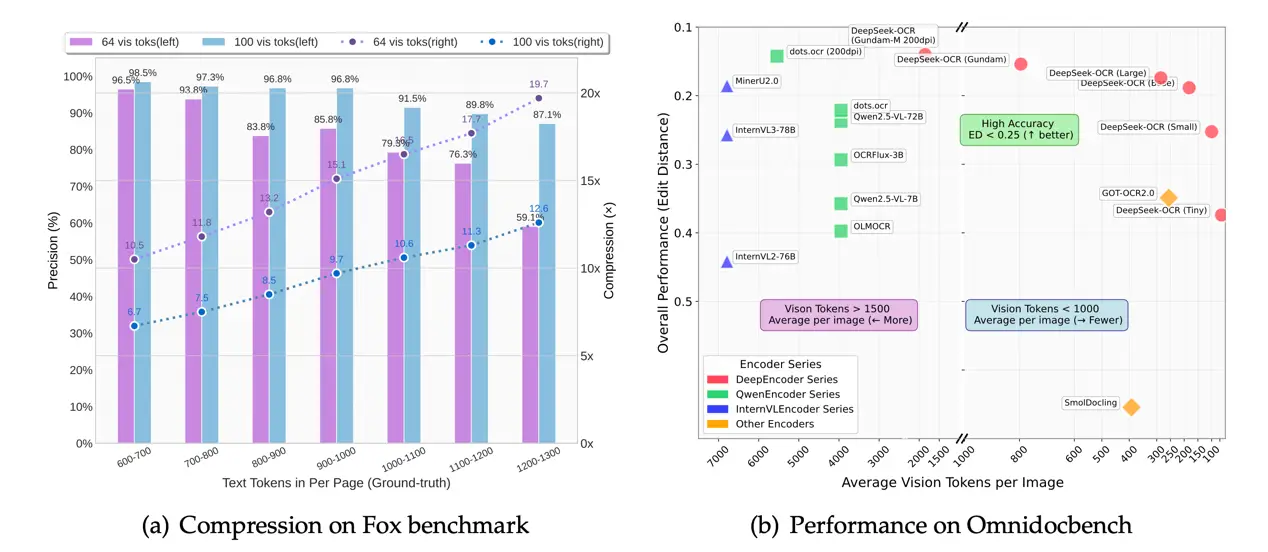
Despite the model's small parameters, research results show that when the text compression ratio is less than 10x, the model's OCR decoding accuracy reaches 97%, and even at a compression ratio of up to 20x, the accuracy remains at 60%. Using an A100-40GB GPU, over 200,000 pages of model training data can be generated in a single day.
This means that while a typical OCR requires 10,000 tokens to read an entire document, this model might only require 1,000, and still accurately interpret the information.
Thanks to the diversity of its training data, the paper states that DeepSeek-OCR is capable of not only recognizing text but also understanding document layout and diagram structure. In some ways, this is no longer a traditional OCR, but more like a "document understanding engine."
The paper mentions a benchmark called OmniDocBench, which is specifically designed to test complex document comprehension capabilities. On this benchmark, DeepSeek-OCR surpasses GOT-OCR 2.0 and MinerU 2.0, both of which are currently leading open-source OCR models, using fewer visual tokens. This is a very powerful approach.
Making AI Memory More Human-Like
In the paper, DeepSeek also addressed the AI "memory" and "forgetting" mechanisms that have long plagued the industry.
Deep learning models store memory in a distributed parameter format. This unstructured storage causes traditional neural networks to overwrite the parameter space of old knowledge with new knowledge when learning new tasks, preventing the model from performing coherent reasoning like humans.
DeepSeek's approach is to enable AI to "remember what needs to be remembered and forget what needs to be forgotten" through a visual-text compression paradigm and a dynamic hierarchical forgetting mechanism.
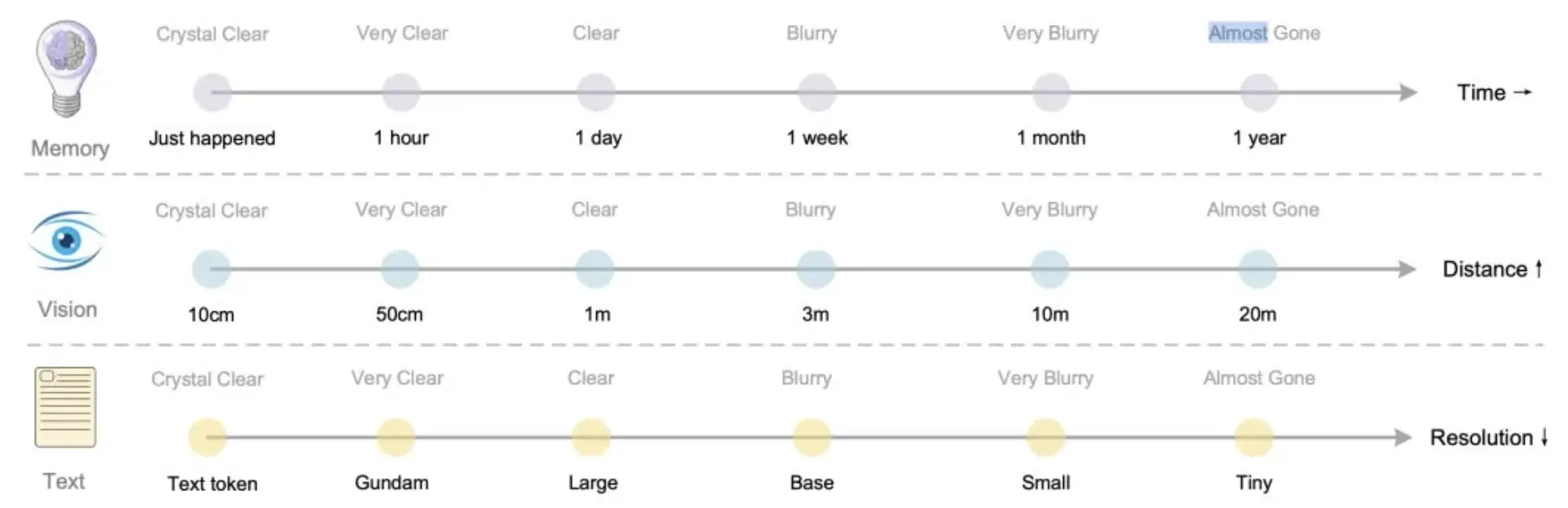
The core idea is to convert text information into visual tokens, achieve efficient memory management through optical compression, and dynamically adjust information retention by simulating the human forgetting curve.
The core component, DeepEncoder, plays a key role in this process. Just 50-100 visual tokens can restore 1,000 words of text, saving nearly 10x the computational effort.
This compression isn't simply a dimensionality reduction, but rather a combination of "attention mechanisms and structured training" to prioritize the information most critical to model reasoning. This approach, similar to the human cognitive pattern of "grasping the headline before looking at the details" when reading, removes unimportant information noise.
The researchers further explained how to make the model's memory model more human-like: for recent memories, they can render them into high-resolution images, retaining high-fidelity information with a large number of tokens. For long-term memories, they can scale them into smaller, blurrier images, retaining information with a small number of tokens, thereby achieving natural forgetting and compression.
Although this research is still in its early stages of exploration, DeepSeek's innovative approach is indeed making AI more human-like.
Three Authors
This paper has three authors: Haoran Wei, Yaofeng Sun, and Yukun Li.
- Haoran Wei, the paper's lead author, previously led the development of the popular GOT-OCR 2.0 project. DeepSeek-OCR can be said to continue the innovative technical path of that project. According to previous paper information, Haoran Wei also worked at Step Star.
- Yaofeng Sun, a graduate of Peking University's Turing Class in Computer Science, joined DeepSeek in 2023 and has participated in research on models such as DeepSeek-r1, DeepSeek-v3, and DeepSeek-v2.
- Yukun Li also participated in research on several models, including DeepSeek-v2/v3, and has nearly 10,000 Google Scholar citations.
GitHub: https://github.com/deepseek-ai/DeepSeek-OCR
Hugging Face: https://huggingface.co/deepseek-ai/DeepSeek-OCR



